
목적
- CPU 이용의 기본 단위가 된 스레드를 이해한다.
실천 목표
- 다양한 CPU 스케줄링 알고리즘을 설명한다.
- 스케줄링 기준에 따라 CPU 스케줄링 알고리즘을 평가한다.
한정된 CPU (코어) 자원과 수많은 프로세스(및 스레드)
- 한정된 CPU (코어)를 효율적으로 할당하기 위한 스케줄링 필요
기본적인 개념 정리
–
- CPU 스케줄러
- 한정된 CPU (코어)를 효율적으로 할당하기 위한 스케줄링 필요
- 준비(Ready) 상태인 프로세스 중 어떤 프로세스에게 CPU (코어)를 할당할지 선택
- CPU 버스트 사이클과 I/O 버스트 사이클
- CPU 버스트 사이클 : 프로세스 실행 사이클 중 CPU가 필요한 사이클
- I/O 버스트 사이클 : 프로세스 실행 사이클 중 CPU가 필요하지 않은, I/O 사이클
- [참고] CPU 버스트 사이클의 비중이 크면 CPU-Bound, I/O 버스트 사이클의 비중이 크면 I/O-Bound
- 선점(Preemptive) 스케줄링과 비선점(Nonpreemptive) 스케줄링
- 선점 스케줄링 : CPU가 한 프로세스에 할당되면 프로세스가 종료하든지 대기 상태로 전환해 CPU를 방출할 때까지 점유하는 스케줄링 방법
- 비선점 스케줄링 : 프로세스가 종료하거나 대기 상태로 전환하지 않더라도 스케줄링 정책에 의해서 할당된 CPU를 반환하기도 하는 스케줄링 방법
- 디스패처 (Dispatcher)
- CPU 스케줄러가 선택한 프로세스에 CPU 코어의 제어권을 부여하는 모듈
- 다음과 같은 작업을 포함
- 한 프로세스에서 다른 프로세스로 문맥 교환
- 사용자 모드로 전환
- 프로세스를 다시 시작하기 위해 사용자 프로그램의 적절한 위치로 이동(jump)
- PCB를 별도로 저장하고 또다른 PCB를 적재하는 데에는 시간이 소요되므로 디스패치 지연(dispatch latency) 발생 -
스케줄링 기준
- CPU 이용률(Utilization)
- CPU를 이용하는 비율
- 처리량 (Throughput)
- 단위 시간당 완료된 프로세스의 개수
- 총처리 시간 (Turnaround time)
- 프로세스가 제출된(준비큐에 들어온) 시간부터 프로세스가 완료되기까지 소요된 총 시간
- 대기 시간 (Waiting time)
- 프로세스가 제출된(준비큐에 들어온) 시간부터 프로세스가 완료되기까지 소요된 대기(Ready) 시간
- 응답 시간 (Response time)
- 프로세스가 제출된(준비큐에 들어온) 시간부터 프로세스가 응답을 시작하기까지 소요된 시간
스케줄링 알고리즘
- 선입 선처리 스케줄링 (FIFO, First-Come First-Served Scheduling)
- CPU를 먼저 요청하는 프로세스가 CPU를 먼저 할당받음
- (예)
- 프로세스별 CPU 버스트 시간
![2022-10-29-os-cpu-scheduling-02]()
- 0 밀리초에 P1, P2, P3 순으로 도착한 경우
- Gantt 차트
![2022-10-29-os-cpu-scheduling-03]()
- average waiting time = (0 + 24 + 27) / 3 = 17
- average turnaround time = (24 + 27 + 30) / 3 = 81
- Gantt 차트
- 0 밀리초에 P2, P3, P1 순으로 도착한 경우
- Gantt 차트
![2022-10-29-os-cpu-scheduling-04]()
- average waiting time = (6 + 0 + 3) / 3 = 3
- average turnaround time = (30 + 3 + 6) / 3 = 13
- Gantt 차트
- 프로세스별 CPU 버스트 시간
- 프로세스의 도착 순서에 따라 성능 평가 결과의 편차가 큼
- 호위 효과(convoy effect) : CPU 버스트 타임이 짧은 프로세스들이 먼저 처리되도록 허용될 때보다 CPU와 장치 이용률이 저하됨
- 최단 작업 우선 스케줄링 (SJF, Shortest-Job-First Scheduling)
- CPU가 이용 가능해지면, 가장 작은 다음 CPU 버스트를 가진 프로세스가 할당받음
- (예)
- 프로세스별 CPU 버스트 시간
![2022-10-29-os-cpu-scheduling-05]()
- 0 밀리초에 P1, P2, P3, P4가 도착한 경우 (순서 무관)
- Gantt 차트
![2022-10-29-os-cpu-scheduling-06]()
- average waiting time = (3 + 16 + 9 + 0) / 4 = 7
- average turnaround time = (9 + 24 + 16 + 3) / 4 = 13
- Gantt 차트
- 프로세스별 CPU 버스트 시간
- 기본적으로는 비선점(Nonpreemptive)
- 이지만 매 단위시간마다 남은 CPU 버스트 시간을 계산해서 컨텍스트 스위칭 여부를 판단하도록 하는 선점(Preemptive)도 가능
- 이를 SRTF, Shortest-Remaining-Time-First 스케줄링이라고 하기도 함
- 라운드 로빈 스케줄링 (RR, Round-Robin)
- 기본적으로 FCFS에 시분할을 적용해서 선점형(Preemptive)
- 미리 정한 time quantum이 지나면 Ready Queue에서 대기 중인 첫 번째 프로세스에게 CPU 할당
- time quantum에 따라 스케줄링 성능이 좌우됨
- time quantum이 무한대에 가까워지는 경우, FCFS와 동일
- 일반적으로 많이 사용하는 스케줄링
- 우선순위 기반 스케줄링
- 우선순위를 정해서 스케줄링하고, 우선순위가 같은 프로세스에 대해서는 FCFS 적용
- SJF도 사실상 우선순위 기반 스케줄링에 해당
- 우선순위를 정하는 다양한 방법에 따라 여러 가지 스케줄링 알고리즘이 있을 수 있음
- 우선순위 스케줄링은 선점형(Preemptive), 비선점형(Nonpreemptive) 모두 가능
- 이때 우선순위가 낮은 프로세스에 대해 기아(starvation) 현상이 생길 수 있는데, 이를 해결하는 방식으로는 대기 시간(waiting time)이 긴 프로세스에 대해 우선순위를 점진적으로 높여주는 aging 을 이용할 수 있음
- 다중 레벨 큐 스케줄링 (MLQ, Multi-Level Queue)
- 우선순위 별로 Ready Queue를 분리
- 다중 레벨 피드백 큐 스케줄링 (MLFQ, Multi-Level Feedback Queue)
- 우선순위 별로 Ready Queue를 분리하고 각 Ready Queue는 time quantum이 다르며, CPU 버스트 시간이 긴 프로세스에 대해서는 다른 레벨의 Ready Queue에 삽입하는 방법
- 실제 O/S의 스케줄링 알고리즘으로 많이 사용됨
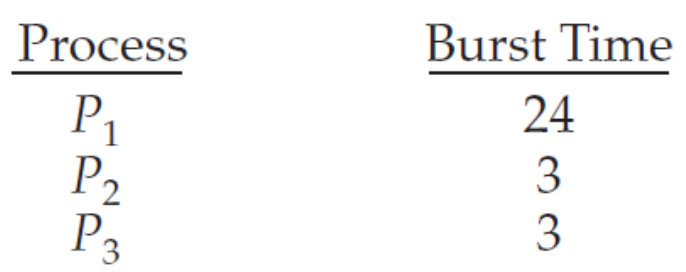




이제는 커널 스레드
- 이제까지 프로세스라고 배웠던 것은 이제 커널 스레드로 치환해서 생각
참고
- 운영체제 공룡책 강의 | 주니온 | 인프런 https://www.inflearn.com/course/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-%EA%B3%B5%EB%A3%A1%EC%B1%85-%EC%A0%84%EA%B3%B5%EA%B0%95%EC%9D%98/dashboard
운영체제 제 10판 Abraham Silberschatz, Peter Baer Galvin, Greg Gagne 저/박민규 역 퍼스트북 2020년 02월 28일 - 운영체제 제 10판 솔루션 https://codex.cs.yale.edu/avi/os-book/OS10/practice-exercises/index-solu.html